Re: [UA-discuss] IDN Implementation Guidelines [RE: Re : And now about phishing...]

Edmon,
it is hardly an issue statistically
I am certainly in agreement in not living in a fact-free world. So, I am collecting data on such sites. I am in the process of setting up a server to monitor 24 x 7 with a homographic domain finder product that we have written. I can tell you from my initial testing that there are a surprising number. Currently, they appear to be for domains which are known world-wide. More as it happens... Thanks, Nalini Elkins CEO and Founder Inside Products, Inc. www.insidethestack.com (831) 659-8360 -------------------------------------------- On Fri, 4/21/17, Edmon Chung <edmon@registry.asia> wrote: Subject: [UA-discuss] IDN Implementation Guidelines [RE: Re : And now about phishing...] To: "'Vittorio Bertola'" <vittorio.bertola@open-xchange.com>, ua-discuss@icann.org, "'Asmus Freytag'" <asmusf@ix.netcom.com> Date: Friday, April 21, 2017, 3:15 AM Starting a separate thread to focus on the IDN Implementation Guidelines Discussion. For the Draft IDN Guidelines you pointed to, please do submit your comments into the still open public comments period (recently extended):https://www.icann.org/public-comments/idn-guidelines-2017-03-03-en To the specific issue of wholescript confusables, there is a further explanation in point 17 why the current recommendation is a "may" rather than a "must"... But if we feel strongly it should move to a must, please do submit your comments in. As for our work at UASG, I feel that it is probably a good idea to collect the counter arguments. I recall there was a phishing/security report a couple years ago that highlighted the issue and indicated that while this (used to be "paypal" example), is possible it is hardly an issue statistically. Does anyone have that report/link? Edmon From: ua-discuss-bounces@icann.org [mailto:ua-discuss-bounces@icann.org] On Behalf Of Vittorio Bertola Sent: Friday, 21 April 2017 17:04 PM To: ua-discuss@icann.org; Asmus Freytag <asmusf@ix.netcom.com> Subject: Re: [UA-discuss] Re : And now about phishing... Il 21 aprile 2017 alle 0.52 Asmus Freytag <asmusf@ix.netcom.com> ha scritto: If you think about it, the following recommendation at the end is anathema to "Universal acceptance":"Zheng is encouraging Firefox users to limit their exposure to the bug by going to the browser’s about:config settings and setting network.IDN_show_punycode to true. By doing this Firefox will always display IDN domains in its Punycode form, something that should make it easier to identify malicious domains, the researcher claims."If you do that, you implicitly assume that only the "non-IDN" links are "real", in other words, you assume an English-only environment. (When stuff is displayed as punicode, you usually can't tell what domain it is, except you can guess for some European ones with very few special characters, but you can't be sure unless the Unicode form is at least also displayed, which I think is not what that config change means).Hello,excuse me if I jump into a discussion having just joined the list, but this issue is really troubling me for at least two reasons.First, many news sources are now filling up with calls and guides for disabling IDNs in browsers altogether, which is a death call for universal acceptance. It all started with this horrible post by Wordfence's CEO, basically equating IDNs to an instrument conceived for phishing:https://www.wordfence.com/blog/2017/04/chrome-firefox-unicode-phishing/It would be really good if anyone knew him and could have a chat with him, maybe even convince him to help spreading a better view of the issue.Secondly, browser makers are now reacting in opposite ways:1) Microsoft's browser (AFAIK) will enable or disable the display of Unicode in the URL bar depending on the operating system's language;2) Google's browser, with a newly released patch, will not display Unicode IDNs in ASCII TLDs if the IDNs are whole-script confusables ( https://codereview.chromium.org/2683793010 );3) Mozilla's browser will explicitly always display Unicode IDNs regardless of whether this may be used for phishing ( https://wiki.mozilla.org/IDN_Display_Algorithm_FAQ and https://bugzilla.mozilla.org/show_bug.cgi?id=1332714 ). However, multiple online sources are now advising people to use a Firefox configuration option that allows to disable the display of IDNs altogether.(Don't know about Apple, Opera and others.)As you see, this is going to hamper the usability of IDNs in URLs and, even worse, make it entirely unpredictable, depending on the user's browser choice.The only real solution to this is that all registries treat whole script confusables as variants, so that they cannot be registered to anyone different than the owner of the equivalent ASCII domain. Unicode TR-39 allows to do this programmatically. However, I just checked the proposed draft IDN guidelines that are currently undergoing public consultation at ICANN:https://www.icann.org/en/system/files/files/draft-idn-guidelines-03mar17-en.... point 16, they say that the registry "may" do this, but that should really be a "must". If this does not happen, there will be more of these situations and the risk that all the Western world will then disable IDNs in URLs for good is quite significant. I think that this group could do several useful things:a) promote a better public understanding of the issue, countering the trend that "IDN URLs are for phishing";b) encourage browser makers to elaborate a common approach;c) push for ICANN and the registries to free the Internet from whole-script confusables.Regards,-- Vittorio Bertola Research & Innovation Engineer Cell:+39 348 7015022Skype:in-skype-ox@bertola.euEmail:vittorio.bertola@open-xchange.com Twitter: @openexchange - Facebook: OpenXchange - Web: www.open-xchange.comOpen-Xchange AG, Rollnerstr. 14, 90408 Nuremberg, District Court Nuremberg HRB 24738 Managing Board: Rafael Laguna de la Vera, Carsten Dirks, Uwe Reumuth Chairman of the Board: Richard Seibt European Office: Open-Xchange GmbH, Olper Huette 5f, D-57462 Olpe, Germany, District Court Siegen, HRB 8718 Managing Directors: Frank Hoberg, Martin Kauss US Office: Open-Xchange. Inc., 530 Lytton Avenue, Palo Alto, CA 94301, USA Confidentiality Warning: This message and any attachments are intended only for the use of the intended recipient(s), are confidential, and may be privileged. If you are not the intended recipient, you are hereby notified that any review, retransmission, conversion to hard copy, copying, circulation or other use of this message and any attachments is strictly prohibited. If you are not the intended recipient, please notify the sender immediately by return e-mail, and delete this message and any attachments from your system.

Thanks Nalini, Share that view, and yes, it was small number when we spoke two years ago. Besides paypal, apple, epic, there is as much brands as you want, which can be made from just Cyrillic chars: Coca-cola, Pepsi, Opel, IBM... And these are just brand names with Cyrillic... more of them can be made with other scripts (Armenian, Georgian, Greek, Arabic...). Also agree entirely with Vittorio, and just want to add another layer of the problem - epic.com example use https, and while GeoTrust and at least one other CA have stopped issuing automated certificated for IDNs sometime ago for other reasons, this trend will be expected for others to follow. So, we need to address this issue and try to explain also to end users what is this (f.e. there is one explanation, which is not entirely ok: https://en.wikipedia.org/wiki/IDN_homograph_attack). Cheers, Dusan -----Original Message----- From: ua-discuss-bounces@icann.org [mailto:ua-discuss-bounces@icann.org] On Behalf Of nalini.elkins@insidethestack.com Sent: Friday, April 21, 2017 4:12 PM To: 'Vittorio Bertola' <vittorio.bertola@open-xchange.com>; ua-discuss@icann.org; 'Asmus Freytag' <asmusf@ix.netcom.com>; Edmon Chung <edmon@registry.asia> Subject: Re: [UA-discuss] IDN Implementation Guidelines [RE: Re : And now about phishing...] Edmon,
it is hardly an issue statistically
I am certainly in agreement in not living in a fact-free world. So, I am collecting data on such sites. I am in the process of setting up a server to monitor 24 x 7 with a homographic domain finder product that we have written. I can tell you from my initial testing that there are a surprising number. Currently, they appear to be for domains which are known world-wide. More as it happens... Thanks, Nalini Elkins CEO and Founder Inside Products, Inc. www.insidethestack.com (831) 659-8360 -------------------------------------------- On Fri, 4/21/17, Edmon Chung <edmon@registry.asia> wrote: Subject: [UA-discuss] IDN Implementation Guidelines [RE: Re : And now about phishing...] To: "'Vittorio Bertola'" <vittorio.bertola@open-xchange.com>, ua-discuss@icann.org, "'Asmus Freytag'" <asmusf@ix.netcom.com> Date: Friday, April 21, 2017, 3:15 AM Starting a separate thread to focus on the IDN Implementation Guidelines Discussion. For the Draft IDN Guidelines you pointed to, please do submit your comments into the still open public comments period (recently extended):https://www.icann.org/public-comments/idn-guidelines-2017-03-03-en To the specific issue of wholescript confusables, there is a further explanation in point 17 why the current recommendation is a "may" rather than a "must"... But if we feel strongly it should move to a must, please do submit your comments in. As for our work at UASG, I feel that it is probably a good idea to collect the counter arguments. I recall there was a phishing/security report a couple years ago that highlighted the issue and indicated that while this (used to be "paypal" example), is possible it is hardly an issue statistically. Does anyone have that report/link? Edmon From: ua-discuss-bounces@icann.org [mailto:ua-discuss-bounces@icann.org] On Behalf Of Vittorio Bertola Sent: Friday, 21 April 2017 17:04 PM To: ua-discuss@icann.org; Asmus Freytag <asmusf@ix.netcom.com> Subject: Re: [UA-discuss] Re : And now about phishing... Il 21 aprile 2017 alle 0.52 Asmus Freytag <asmusf@ix.netcom.com> ha scritto: If you think about it, the following recommendation at the end is anathema to "Universal acceptance":"Zheng is encouraging Firefox users to limit their exposure to the bug by going to the browser’s about:config settings and setting network.IDN_show_punycode to true. By doing this Firefox will always display IDN domains in its Punycode form, something that should make it easier to identify malicious domains, the researcher claims."If you do that, you implicitly assume that only the "non-IDN" links are "real", in other words, you assume an English-only environment. (When stuff is displayed as punicode, you usually can't tell what domain it is, except you can guess for some European ones with very few special characters, but you can't be sure unless the Unicode form is at least also displayed, which I think is not what that config change means).Hello,excuse me if I jump into a discussion having just joined the list, but this issue is really troubling me for at least two reasons.First, many news sources are now filling up with calls and guides for disabling IDNs in browsers altogether, which is a death call for universal acceptance. It all started with this horrible post by Wordfence's CEO, basically equating IDNs to an instrument conceived for phishing:https://www.wordfence.com/blog/2017/04/chrome-firefox-unicode-phishing/It would be really good if anyone knew him and could have a chat with him, maybe even convince him to help spreading a better view of the issue.Secondly, browser makers are now reacting in opposite ways:1) Microsoft's browser (AFAIK) will enable or disable the display of Unicode in the URL bar depending on the operating system's language;2) Google's browser, with a newly released patch, will not display Unicode IDNs in ASCII TLDs if the IDNs are whole-script confusables ( https://codereview.chromium.org/2683793010 );3) Mozilla's browser will explicitly always display Unicode IDNs regardless of whether this may be used for phishing ( https://wiki.mozilla.org/IDN_Display_Algorithm_FAQ and https://bugzilla.mozilla.org/show_bug.cgi?id=1332714 ). However, multiple online sources are now advising people to use a Firefox configuration option that allows to disable the display of IDNs altogether.(Don't know about Apple, Opera and others.)As you see, this is going to hamper the usability of IDNs in URLs and, even worse, make it entirely unpredictable, depending on the user's browser choice.The only real solution to this is that all registries treat whole script confusables as variants, so that they cannot be registered to anyone different than the owner of the equivalent ASCII domain. Unicode TR-39 allows to do this programmatically. However, I just checked the proposed draft IDN guidelines that are currently undergoing public consultation at ICANN:https://www.icann.org/en/system/files/files/draft-idn-guidelines-03mar17-en.... point 16, they say that the registry "may" do this, but that should really be a "must". If this does not happen, there will be more of these situations and the risk that all the Western world will then disable IDNs in URLs for good is quite significant. I think that this group could do several useful things:a) promote a better public understanding of the issue, countering the trend that "IDN URLs are for phishing";b) encourage browser makers to elaborate a common approach;c) push for ICANN and the registries to free the Internet from whole-script confusables.Regards,-- Vittorio Bertola Research & Innovation Engineer Cell:+39 348 7015022Skype:in-skype-ox@bertola.euEmail:vittorio.bertola@open-xchange.com Twitter: @openexchange - Facebook: OpenXchange - Web: www.open-xchange.comOpen-Xchange AG, Rollnerstr. 14, 90408 Nuremberg, District Court Nuremberg HRB 24738 Managing Board: Rafael Laguna de la Vera, Carsten Dirks, Uwe Reumuth Chairman of the Board: Richard Seibt European Office: Open-Xchange GmbH, Olper Huette 5f, D-57462 Olpe, Germany, District Court Siegen, HRB 8718 Managing Directors: Frank Hoberg, Martin Kauss US Office: Open-Xchange. Inc., 530 Lytton Avenue, Palo Alto, CA 94301, USA Confidentiality Warning: This message and any attachments are intended only for the use of the intended recipient(s), are confidential, and may be privileged. If you are not the intended recipient, you are hereby notified that any review, retransmission, conversion to hard copy, copying, circulation or other use of this message and any attachments is strictly prohibited. If you are not the intended recipient, please notify the sender immediately by return e-mail, and delete this message and any attachments from your system. --- This email has been checked for viruses by Avast antivirus software. https://www.avast.com/antivirus

On Fri, Apr 21, 2017 at 07:11:00PM +0200, Dusan Stojicevic wrote:
Besides paypal, apple, epic, there is as much brands as you want, which can be made from just Cyrillic chars: Coca-cola, Pepsi, Opel, IBM...
See Asmus's notes, but there's a basic problem here: there is at bottom no way to fix this generally. If you want to expand the character repertoire of identifiers to encompass all the characters humans use, it is going to come with a considerable risk of potential confusion. There is nothing remotely new about this. (The only really new thing here is someone successfully whipping up anxiety over this supposed "bug", and even that is just a rerun of previous similar events.) I think this group could do some useful things. For instance, if we funded open code for variant calculation and found some additional people who were willing to learn about the details (this requires at least actually reading the Unicode spec) to pour into the i18n issues, I think that would be a contribution. Best regards, A -- Andrew Sullivan ajs@anvilwalrusden.com

On 4/21/2017 11:47 AM, Andrew Sullivan wrote:
On Fri, Apr 21, 2017 at 07:11:00PM +0200, Dusan Stojicevic wrote:
Besides paypal, apple, epic, there is as much brands as you want, which can be made from just Cyrillic chars: Coca-cola, Pepsi, Opel, IBM... See Asmus's notes, but there's a basic problem here: there is at bottom no way to fix this generally. If you want to expand the character repertoire of identifiers to encompass all the characters humans use, it is going to come with a considerable risk of potential confusion. There is nothing remotely new about this. (The only really new thing here is someone successfully whipping up anxiety over this supposed "bug", and even that is just a rerun of previous similar events.)
I think this group could do some useful things. For instance, if we funded open code for variant calculation and found some additional people who were willing to learn about the details (this requires at least actually reading the Unicode spec) to pour into the i18n issues, I think that would be a contribution.
Agreed. Two observations: (1) Understanding how to use and define variants is a first step. I created a draft to explain the technical side of that, but it's stuck in the ietf because of alleged controversies about its status while I get clear indication from the comments that nobody actually read much of anything past the abstract. >:( For the record, here it is: https://tools.ietf.org/html/draft-freytag-lager-variant-rules-05 feedback welcome. (2) There is considerable work being done on creating data that are better focused than what UTR#39 has; and in format more directly usable for anyone following RFC 7940. The trick is in collecting and publishing this somewhere. A./
Hi Andrew, If I want to expand the character repertoire of identifiers to encompass all the chars humans use, I will get - Unicode. :) As a person who want Internet on Unicode, not on ASCII, this is something you can expect from me. :) Now seriously, I agree mostly with you, "bug" is not new (the guy just invest few dollars to get some thousand dollars for telling to Google what we knew for many years), but - if we start to address this problem just as "ASCII brands confusion with other scripts (and most brands are written in Latin script)", soon we will get back to ASCII Internet - which is just starting with making IDNs second-class URLs, and ending with no interest from users. And I agree with you - we will have a lot of potential confusion (whatever we do to solve this), and that's what we need to discuss - maybe I am wrong, maybe we need to use languages not only scripts, not sure - but this way, how developers and registries are addressing this issue, is leading to an end of IDNs as something usable. And agree with you that this group can do useful things, that's why I am here :) Cheers, Dusan -----Original Message----- From: ua-discuss-bounces@icann.org [mailto:ua-discuss-bounces@icann.org] On Behalf Of Andrew Sullivan Sent: Friday, April 21, 2017 8:48 PM To: ua-discuss@icann.org Subject: Re: [UA-discuss] IDN Implementation Guidelines [RE: Re : And now about phishing...] On Fri, Apr 21, 2017 at 07:11:00PM +0200, Dusan Stojicevic wrote:
Besides paypal, apple, epic, there is as much brands as you want, which can be made from just Cyrillic chars: Coca-cola, Pepsi, Opel, IBM...
See Asmus's notes, but there's a basic problem here: there is at bottom no way to fix this generally. If you want to expand the character repertoire of identifiers to encompass all the characters humans use, it is going to come with a considerable risk of potential confusion. There is nothing remotely new about this. (The only really new thing here is someone successfully whipping up anxiety over this supposed "bug", and even that is just a rerun of previous similar events.) I think this group could do some useful things. For instance, if we funded open code for variant calculation and found some additional people who were willing to learn about the details (this requires at least actually reading the Unicode spec) to pour into the i18n issues, I think that would be a contribution. Best regards, A -- Andrew Sullivan ajs@anvilwalrusden.com --- This email has been checked for viruses by Avast antivirus software. https://www.avast.com/antivirus
On 4/21/2017 10:11 AM, Dusan Stojicevic wrote:
And these are just brand names with Cyrillic... more of them can be made with other scripts (Armenian, Georgian, Greek, Arabic...).
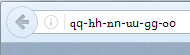
Just hold on a minute. We've just done a pretty thorough first pass over cross-script homoglyphs (the identical-looking code points, not the "looks the same if you squint at them at arms-length" variety). The conclusion is that Armenian has a small number of letters (q, h, n, u, o, and possibly g) that might qualify. In some fonts, they are rendered practically identically, in others not so much: They are also less "useful" for whole script confusables, as they lack certain high frequency letters like "e", "a", "i", and "s" /Armenian/// x x x x x x *etaoinshrdlcumwfgypbvkjxqz***x xxx xx x xx x /Cyrillic / Now for Georgian, the same review concluded there is no high fidelity overlap (near identical pair of code points). In Greek you have a real issue only to the extent that you show the address in uppercase. Most of the lowercase letters are pretty distinct (except for omicron, and nu (ν) looks more than a little bit like "v"). We had a strong debate on whether to take uppercase into account when deciding which code points constitute cross-script variants. The conclusion we had was that the protocol is limited to lowercase for a reason. If you consider uppercase, you get different pairs based on the two cases. Capital N looks like "N", lowercase nu looks like "v". If you require variants to be transitive (very necessary for optimized evaluation), then you get "n" as a variant of "v" in Latin! It works like this: Lowercase n is a case variant of cap N, N is a (homoglyph-)variant of Cap Nu, Cap Nu is a (case-)variant of lowercase nu, lowercase nu is a (homoglyph-)variant of v. When you traverse this chain, which is what defines transitivity, you can get from "n" to "v" inside the same script. We figured that we had reached the limit of what you can address with variants in the registries at this point. Finally, as for Arabic, I would like to see an example of a Latin label spoofed using only Arabic letters. (It's possible to write "English" using Chinese characters that vaguely look like letters of the alphabet, but while you can read such texts, they look rather odd).
Also agree entirely with Vittorio, and just want to add another layer of the problem - epic.com example use https, and while GeoTrust and at least one other CA have stopped issuing automated certificated for IDNs sometime ago for other reasons, this trend will be expected for others to follow.
Displaying some details about the domain/certificate owner (see my previous message) would seem to be more useful than showing an IDN as impenetrable xn-- label. The former works for phishing attacks against any scripts, the latter is only useful for people who can be expected to work entirely without IDNs. A./
{kind=link}
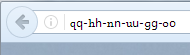
Hi Asmus, As a chair of Cyrillic GP, I must assure you that I know all those things you have just explained. J Thanks for very good explanation, and yes, we done wonderful job with cross-script homoglyphs, but it seems to me that I need to explain something else> in my mind there is no question of Latin brand written on Arabic script. I use to work for brand Политика / Cyrillic brand, so I am thinking about Cyrillic brands on Arabic, Armenian, Greek, Latin… All in all - I was saying that because of possible confusion between all scripts – not only related to „ASCII brands“. And again, maybe I am wrong, just discussing J For certificates – in other email. Cheers, Dusan From: Asmus Freytag (c) [mailto:asmusf@ix.netcom.com] Sent: Friday, April 21, 2017 9:01 PM To: Dusan Stojicevic <dusan@dukes.in.rs>; nalini.elkins@insidethestack.com; 'Vittorio Bertola' <vittorio.bertola@open-xchange.com>; ua-discuss@icann.org; 'Edmon Chung' <edmon@registry.asia> Subject: Re: [UA-discuss] IDN Implementation Guidelines [RE: Re : And now about phishing...] On 4/21/2017 10:11 AM, Dusan Stojicevic wrote: And these are just brand names with Cyrillic... more of them can be made with other scripts (Armenian, Georgian, Greek, Arabic...). Just hold on a minute. We've just done a pretty thorough first pass over cross-script homoglyphs (the identical-looking code points, not the "looks the same if you squint at them at arms-length" variety). The conclusion is that Armenian has a small number of letters (q, h, n, u, o, and possibly g) that might qualify. In some fonts, they are rendered practically identically, in others not so much: They are also less "useful" for whole script confusables, as they lack certain high frequency letters like "e", "a", "i", and "s" Armenian x x x x x x etaoinshrdlcumwfgypbvkjxqz x xxx xx x xx x Cyrillic Now for Georgian, the same review concluded there is no high fidelity overlap (near identical pair of code points). In Greek you have a real issue only to the extent that you show the address in uppercase. Most of the lowercase letters are pretty distinct (except for omicron, and nu (ν) looks more than a little bit like "v"). We had a strong debate on whether to take uppercase into account when deciding which code points constitute cross-script variants. The conclusion we had was that the protocol is limited to lowercase for a reason. If you consider uppercase, you get different pairs based on the two cases. Capital N looks like "N", lowercase nu looks like "v". If you require variants to be transitive (very necessary for optimized evaluation), then you get "n" as a variant of "v" in Latin! It works like this: Lowercase n is a case variant of cap N, N is a (homoglyph-)variant of Cap Nu, Cap Nu is a (case-)variant of lowercase nu, lowercase nu is a (homoglyph-)variant of v. When you traverse this chain, which is what defines transitivity, you can get from "n" to "v" inside the same script. We figured that we had reached the limit of what you can address with variants in the registries at this point. Finally, as for Arabic, I would like to see an example of a Latin label spoofed using only Arabic letters. (It's possible to write "English" using Chinese characters that vaguely look like letters of the alphabet, but while you can read such texts, they look rather odd). Also agree entirely with Vittorio, and just want to add another layer of the problem - epic.com example use https, and while GeoTrust and at least one other CA have stopped issuing automated certificated for IDNs sometime ago for other reasons, this trend will be expected for others to follow. Displaying some details about the domain/certificate owner (see my previous message) would seem to be more useful than showing an IDN as impenetrable xn-- label. The former works for phishing attacks against any scripts, the latter is only useful for people who can be expected to work entirely without IDNs. A./ --- This email has been checked for viruses by Avast antivirus software. https://www.avast.com/antivirus
{kind=link}
Hi, On Fri, Apr 21, 2017 at 02:11:37PM +0000, nalini.elkins@insidethestack.com wrote:
I am certainly in agreement in not living in a fact-free world. So, I am collecting data on such sites. I am in the process of setting up a server to monitor 24 x 7 with a homographic domain finder product that we have written.
Is that the homograph finder you had before? I seem to recall discussing some limitations it had some while ago; have those been fixed? Best regards, A -- Andrew Sullivan ajs@anvilwalrusden.com
participants (5)
-
 Andrew Sullivan
Andrew Sullivan -
 Asmus Freytag
Asmus Freytag -
Asmus Freytag (c)
-
 Dusan Stojicevic
Dusan Stojicevic -
 nalini.elkins@insidethestack.com
nalini.elkins@insidethestack.com